

Ocena jakości tłumaczenia wygenerowanego przez AI – case study agencji locatheart
Dużo wody w Wiśle upłynęło, odkąd ostatni raz na łamach strony locatheart poruszaliśmy temat generatywnej sztucznej inteligencji (GenAI). Przez ten czas we wszystkich obszarach naszego życia rozprzestrzeniły się treści tworzone w pełni lub w znacznym stopniu przez narzędzia takie jak ChatGPT, Claude, Grok i Perplexity.
Nie inaczej jest w przypadku tłumaczeń – chociażby YouTube w wielu sytuacjach pozwala na tłumaczenie filmów na żywo (przez napisy, a także dubbing „live”), korzystając z funkcji Tłumacza Google, który na wielu płaszczyznach operuje w sposób analogiczny do modeli AI. Wydaje się jednak, że obecnie nieco więcej osób do doraźnego tłumaczenia tekstów używa narzędzi stricte AI, nie zaś Google Translate czy DeepL.
Według danych witryny StatCounter na marzec 2026 roku przeważająca większość internautów w dalszym ciągu korzysta przede wszystkim z chatbota firmy OpenAI – czyli ChatGPT. Ponadto sam technologiczny gigant podaje, iż wśród ok. 900 milionów użytkowników aktywnych każdego tygodnia kont płatnych jest ok. 50 milionów (5,6%).
Bazując na tych informacjach, postanowiliśmy wypróbować najpopularniejszą usługę AI – tj. ChatGPT – w wersji darmowej. Zastosowany do testów tłumaczeń model to GPT-5.3.
W dzisiejszym artykule sprawdzimy zatem, jak na chwilę obecną z tłumaczeniem radzi sobie najpopularniejszy model generatywnej AI, oraz odpowiemy na ważne pytanie: „Jak ocenić jakość tłumaczenia wygenerowanego przez AI?”.
Zadanie 1
Pierwszy tekst, który „zleciliśmy” narzędziu AI do tłumaczenia, to artykuł (case study) ze strony internetowej locatheart: Football game localisation into Polish. W wyjściowym prompcie poprosiliśmy ChatGPT o przetłumaczenie wklejonego tekstu na język polski.
Powierzchowna analiza przekładu, który otrzymaliśmy, sugeruje, że jest on stosunkowo dobrej jakości. ChatGPT nie tłumaczy „jeden do jednego”, stosuje właściwe w danym miejscu frazeologizmy, jego styl jest raczej poprawny, a cały artykuł w tłumaczeniu maszynowym czyta się dość dobrze.
Mimo to nawet w tym niedługim tekście natrafiliśmy na kilka błędów, które są warte nadmienienia, ponieważ dobrze ilustrują „systemowe” problemy narzędzi AI w zakresie tłumaczeń.
| Tekst wyjściowy (EN) | Tłumaczenie AI (PL) | Komentarz LAH |
| Not long before UEFA Euro 2024 | Niedługo przed mistrzostwami UEFA Euro 2024 | Tłumaczenie jest technicznie i terminologicznie poprawne, jego brzmienie jest jednak dość „korporacyjne” – trochę tak, jakby odgórnie polecono używać oficjalnej nazwy turnieju („UEFA Euro 2024”), która akurat po angielsku jest naturalna. Zdecydowanie zgrabniejszym rozwiązaniem byłoby np. „Niedługo przed mistrzostwami Europy w piłce nożnej” lub „Niedługo przed Euro 2024”. |
| Do you want to localise gaming content? | Czy chcesz zlokalizować treści gamingowe? | Ten konkretny fragment to CTA – musi zatem dobrze brzmieć i być „chwytliwy”. Zdecydowanie lepiej sprawdziłaby się tu wersja bez „czy”; oprócz tego można podać w wątpliwość to, czy przymiotnik „gamingowe” jest odpowiedni – nam wydaje się, że w polszczyźnie odnosi się raczej wyłącznie do gier wideo i związanej z nimi publicystyki. |
| What’s more, it can be trusted when it comes to the correct spelling of players’ or clubs’ names | Co więcej, można jej zaufać w kwestii poprawnej pisowni nazw zawodników czy klubów | Zdecydowanie najpoważniejszy błąd w omawianym tłumaczeniu – „players’ (…) names” to ich imiona i nazwiska; „nazwy” odnoszą się do bytów abstrakcyjnych, nie ludzi. Oczywiście można łatwo wydedukować, skąd wziął się błąd: po prostu w języku angielskim to samo słowo pasuje zarówno do zawodników, jak i do klubów – ale nie w polszczyźnie. |
| whenever there were any doubts or questions, the translator was ready to answer them | w razie wątpliwości tłumacz był gotowy do udzielenia wyjaśnień | Sens został zachowany, ale wydźwięk jest mocno urzędowy – można pomyśleć, że chodzi o składanie wyjaśnień dotyczących błędnie wypełnionego formularza PIT. |
| our project manager received general remarks concerning potential reception of the game by Polish audiences | kierownik projektu otrzymał także ogólne uwagi dotyczące potencjalnego odbioru gry przez polskich użytkowników | Osoba (PM), o której mowa w tym zdaniu, jest kobietą; oczywiście ani AI, ani nawet „żywy” tłumacz (spoza LAH) nie musi tego wiedzieć, jednak człowiek zawsze może dopytać – maszyna natomiast tego nie zrobiła. |
| It was noticed that the quiz features way too many questions about British footballers | Zauważono, że quiz zawiera zdecydowanie zbyt wiele pytań dotyczących brytyjskich piłkarzy | Forma „zauważono” razi – jest mocno bezosobowa. |
Czy przetłumaczony przez AI tekst artykułu ze strony locatheart jest zrozumiały i przekazuje odpowiednie informacje? Tak. Czy zamieścilibyśmy go w niezmienionej formie online? Zdecydowanie nie. Gdybyśmy z jakiegoś teoretycznego powodu byli zmuszeni skorzystać z tłumaczenia AI, redakcja i korekta i tak zostałyby oddelegowane do pracownika/pracownicy LAH z wykształceniem kierunkowym.
Ktoś mógłby jednak zauważyć, że dalszą obróbkę tłumaczenia wygenerowanego przez AI także można „zlecić” sztucznej inteligencji. Sprawdźmy zatem, co uzyskamy w takim scenariuszu. W obydwu przypadkach zapytaliśmy ChatGPT o przekład, który sam wcześniej (w innej instancji) wytworzył.
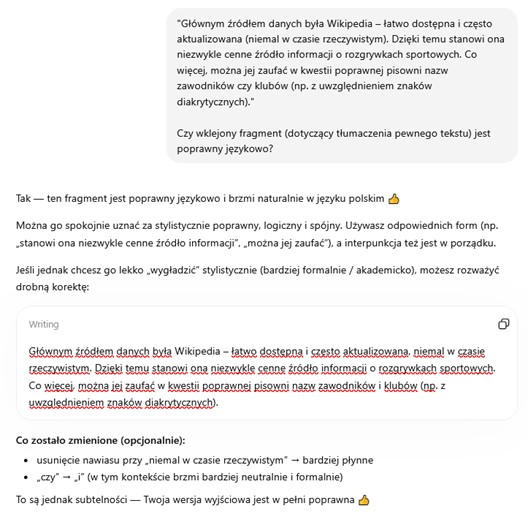
Jak widać, sztuczna inteligencja nie poprawiła fragmentu o „nazwach zawodników”.
Poprosiliśmy także w nowej konwersacji o zredagowanie całości tekstu, a więc o poprawienie pełnego tłumaczenia wykonanego przez AI. W interesującym nas miejscu otrzymaliśmy tak zmieniony fragment:

Treść została zmodyfikowana, jednak jeden błąd został zastąpiony drugim: tym razem mamy do czynienia z „nazwiskami (…) klubów”, co kłuje w oczy bodaj jeszcze bardziej.
Gdyby nie fakt, że polski jest językiem ojczystym pracowników LAH – a angielski „głównym” obcym – nie mielibyśmy jak zorientować się, że przekład wykonany przez AI zawiera niedociągnięcia. Niestety nawet „zlecenie” maszynie redakcji jej własnego przekładu nie rozwiązuje problemu. Wniosek jest jeden: udział człowieka w procesie tłumaczenia jest i prawdopodobnie zawsze będzie niezbędny, aby zniwelować liczbę błędów do absolutnego minimum. Narzędziom AI niestety nie można zaufać.
Zadanie 2
Drugim tekstem, o którego przetłumaczenie zwróciliśmy się do ChatGPT, był inny artykuł z bloga locatheart. Ten przekład zawiera mniej „usterek” niż poprzedni, ale jedno miejsce jest warte zacytowania – dobrze pokazuje to, jak ważny jest naturalny styl wypowiedzi:
EN (oryginał): The era of copy-pasting is falling into oblivion. And no one will miss it! After all, this method is highly monotonous and involves the risk of making simple mistakes (such as copying the content only partially, or mixing up different language versions).
PL (tłumaczenie AI): Czasy kopiowania i wklejania powoli odchodzą do lamusa – i nikt nie będzie za nimi tęsknił! Metoda ta jest bowiem bardzo monotonna i wiąże się z ryzykiem prostych błędów (np. częściowego skopiowania treści lub pomylenia wersji językowych).
Choć wypada pochwalić zgrabne przetłumaczenie „falling into oblivion” jako „odchodzą do lamusa” czy połączenie dwóch zdań z oryginału myślnikiem, to zwrot „częściowe skopiowanie treści” jest niefortunny. Nie oddaje on źródłowego „only partially” – o wiele lepsze byłoby ujęcie tego fragmentu jako np. „skopiowania treści jedynie częściowo” czy nawet „pominięcia części tekstu przy kopiowaniu”.
Zadanie 3
Poprzednie dwa przykłady dotyczyły tekstów raczej dość ogólnych – jak się okazuje, przy tłumaczeniu artykułu o tematyce rolniczej AI myli się jeszcze bardziej.
Na tapet wzięliśmy opis badania preparatu do nawożenia ze strony jego producenta.
Istotny błąd pojawia się już na początku tekstu, jaki wygenerował nam ChatGPT. W angielskim oryginale czytamy: „In these results, Polysulphate increased the yield of oilseed rape by up to 33%, between 200 kg/ha and 1.15 t/ha (T2 gave the best results)”.
Tłumaczenie z wykorzystaniem AI na polski brzmi z kolei następująco: „W przedstawionych wynikach Polysulphate zwiększył plon rzepaku ozimego nawet o 33%, tj. od 200 kg/ha do 1,15 t/ha (najlepsze wyniki uzyskano w wariancie T2)”.
Zależnie od interpretacji przekład może być wręcz skrajnie mylący – można dojść do wniosku, że pierwotny plon rzepaku wynosił 200 kg/ha, a finalny – aż 1,15 t/ha. Byłby to więc wzrost nie o 33%, lecz o niemal 500%! Tymczasem chodzi tu o to, że przyrost plonów mieścił się w zakresie od 200 kg/ha (dość „nieduża” poprawa) do 1,15 t/ha, gdzie ta ostatnia liczba oznaczała wzrost o 1/3 względem uprawy bez zastosowania badanego nawozu.
Uzyskany wskutek tłumaczenia AI fragment jest w najlepszym razie bardzo niejasno sformułowany, a w najgorszym – wprowadza w naprawdę poważny błąd.
Dla porządku można dodać, że w kilku miejscach polskiego tłumaczenia ChatGPT w nawiasie umieścił angielski skrót dla rzepaku ozimego: „WOSR”, który nie jest używany w polszczyźnie.
Zadanie 4
Jako agencja tłumaczeniowa locatheart często prowadzi projekty klientów, którzy wypuszczają na nowe rynki gry bez prądu (ang. tabletop games – głównie gry planszowe i karciane). Z tego względu w naszej analizie nie mogło zabraknąć fragmentu tekstu dotyczącego takiej gry – jest to konkretnie skrócona wersja zasad Dungeons & Dragons opublikowana na Reddicie. (Do chatbota wkleiliśmy całość posta począwszy od fragmentu „** General Gameplay **”).
O ile użyta w tłumaczeniu terminologia czy rozeznanie w dość „żargonowo” rozpisanych regułach były w wykonaniu AI bez zarzutu, o tyle w kilku miejscach ChatGPT zupełnie zignorował część tekstu. Chodzi o te fragmenty:
EN:

PL (AI):

Narzędzie całkowicie pominęło akapit wyjaśniający pod „** Actions **”, a także przymiotnik „visible” i tekst w nawiasie („I presume this means”…).
W poleceniu wydanym ChatGPT nie wspomnieliśmy w żaden sposób o tym, że tłumaczenie ma nie zawierać fragmentów, które mogą wydawać się komentarzami lub uwagami „na marginesie” autora posta. Prawdopodobnie sztuczna inteligencja uznała owe miejsca za nieistotne – ale tego typu strategia, zwłaszcza w tak długich fragmentach tekstu, jest w branży tłumaczeń niedopuszczalna. Nie wydaje się, aby istniał sposób na uniknięcie podobnych błędów bez – co najmniej – redakcji i korekty wykonanych przez osoby władające językiem zarówno źródłowym, jak i docelowym. Gdybyśmy poprosili o tłumaczenie tekstu na język, którego systemu pisma w ogóle nie znamy, nie mielibyśmy żadnej przesłanki, by zorientować się, że któregoś fragmentu po prostu brakuje. Dodatkowo, jak zauważyliśmy wcześniej, redakcja w wykonaniu AI też nie gwarantuje odpowiedniego „podrasowania” tekstu zawierającego błędy.
Jak sprawdzić jakość tłumaczonego tekstu wygenerowanego przez AI?
Przytoczone wyżej faktyczne przykłady tłumaczeń wykonanych przez sztuczną inteligencję wskazują na jedno – aby możliwa była ocena ich jakości, konieczny jest specjalista językowiec. Jego zadaniem będzie podejście do tekstu tak samo jak do przekładu wykonanego przez człowieka – ostatecznie (mimo że nie zawsze jest to możliwe) chodzi o to, by efekt końcowy był nieodróżnialny od treści stworzonej przez człowieka od zera w jego języku ojczystym.
Oczywiście możemy wyobrazić sobie – dość ograniczone – sytuacje, w których tłumaczenie wykonane przez AI i niezredagowane przez człowieka wydaje się akceptowalnym wyjściem. Jeśli na przykład prowadzimy sklep internetowy i chcemy sprzedawać również za granicą, czasami możemy przetłumaczyć za pomocą AI nazwy produktów, a niekiedy także ich opisy. Zazwyczaj są to teksty, które jedynie uzupełniają to, co najistotniejsze – specyfikację produktu i jego zdjęcia – zatem możliwe, że nie będą miały największej wagi pod względem sprzedażowym. Nie sposób jednak z góry założyć, że przy jakiejś nazwie produktu sztuczna inteligencja nie będzie halucynowała i że w tekście zamiast „długopisu” nie pojawi się „zagroda” (oba słowa to po angielsku „pen”) albo w ogóle coś niezwiązanego z naszą ofertą.
Zawsze trzeba zresztą pamiętać, że nienaturalne frazy lub błędy przeinaczające znaczenie mogą zniechęcić potencjalnego klienta. A – jak już wiemy – bez znajomości języka docelowego zwyczajnie brakuje nam możliwości stwierdzenia, czy wygenerowany tekst zawiera takie błędy. Sztuczna inteligencja sama z siebie nie zauważy, że wzrost od 200 kg do 1,15 t to znacznie więcej niż 33% – człowiek raczej najpierw dwa razy się zastanowi.
Zastanawiasz się, jak w erze AI zachować naturalny głos swojej marki? Skontaktuj się z naszymi ekspertami!




Dodaj komentarz