

Tłumaczenie, które zapada w pamięć – czym jest pamięć tłumaczeniowa i w jaki sposób językowcy i agencje wykorzystują ją, by tworzyć doskonałe tłumaczenia?
W jednym z naszych poprzednich artykułów opisaliśmy narzędzia, których używamy, aby usprawnić proces lokalizacji w locatheart. Należy do nich między innymi Trados, narzędzie CAT (jest to oprogramowanie wspierające tłumaczenia), które na rynku tłumaczeniowym jest swoistym złotym standardem. Jedną z jego najbardziej pomocnych funkcji jest pamięć tłumaczeniowa (translation memory – w skrócie TM): „baza danych obejmująca wszystkie poprzednie projekty, w której zostały zapisane teksty źródłowe wraz z towarzyszącymi im tłumaczeniami”.
Klienci agencji tłumaczeń z reguły niewiele wiedzą o TM, ponieważ głównie interesuje ich produkt końcowy – bezbłędny tekst docelowy. Mimo to warto lepiej zrozumieć pamięci tłumaczeniowe. Na nich właśnie oparty jest system wyceny, który jest korzystny dla klienta.
Czym dokładnie jest pamięć tłumaczeniowa?
Stale powiększający się zbiór danych w dwóch wybranych językach następnie służy jako punkt odniesienia dla tłumaczy, którym zostaną przydzielone przyszłe zadania. Mają dzięki temu możliwość wyszukać konkretne frazy, które według nich mogły pojawić się już we wcześniejszych projektach.
Nie jest to jednak najważniejsza cecha pamięci tłumaczeniowych. Jest nią automatyczna funkcja wstawiania propozycji przekładu na użytek tłumacza. Załóżmy, że firma zamówi tłumaczenie umowy sprzedaży. Agencja tłumaczeniowa zrealizuje to zadanie i odeśle wersję docelową. Jakiś czas później pojawi się zlecenie dotyczące zbliżonego rodzaju umowy – zawieranej z innym podmiotem, z nieco różniącymi się postanowieniami, ale w gruncie rzeczy bardzo podobnej.
Pamięci tłumaczeniowe w akcji
Tego typu sytuacja jest klasycznym przykładem użycia pamięci tłumaczeniowych. TM przechowuje dwujęzyczną wersję pierwszej umowy w całości. Jako że jest podpięta pod projekt w Tradosie, program widzi, że niektóre zdania są identyczne w przypadku obydwu umów, w związku z czym automatycznie uzupełnia wybrane segmenty, korzystając z pamięci tłumaczeniowej.
W podanym przykładzie stanie się tak w większości zdań. Zdarzyć się może, że program uzupełni dany segment pomimo drobnych różnic, na przykład w nazwie jednej z firm. Wtedy poinformuje użytkownika, że segmenty nie są identyczne. Podobne, owszem, ale nie słowo w słowo.
Rolą tłumacza jest wówczas zaktualizowanie treści, które się różnią, i zapisanie nowej wersji. W przypadku braku odpowiedników w poprzednich tekstach tłumaczenie fragmentu jest wykonywane od podstaw. Jednak już teraz lwia część zadania została zautomatyzowana, dzięki czemu czas pracy uległ znacznemu skróceniu.
W zależności od podanych wytycznych tłumacz może zaakceptować uzupełnioną treść bez sprawdzania lub zweryfikować, czy pierwszy projekt nie zawierał żadnych błędów. Jednak koniec końców, zaopatrzeni w dodatkową porcję czasu, językowcy mogą szybciej wykonać zlecenie, a tym samym klient szybciej otrzyma gotowy tekst.

Pamięć tłumaczeniowa nie jest tłumaczeniem maszynowym
Prawdopodobnie należy podkreślić, że program korzystający z pamięci tłumaczeniowej nie ma nic wspólnego z tłumaczeniem maszynowym. Oba te procesy odbywają się w przestrzeni elektronicznej, jednak na tym podobieństwa się kończą. W tłumaczeniu maszynowym treści są automatycznie przekładane na język docelowy przez program komputerowy w oparciu o algorytmy, bazy danych i zbiór reguł.
Z kolei pamięć tłumaczeniowa to narzędzie, z którego tłumacze mogą korzystać, aby ułatwić sobie pracę. Jak wspomnieliśmy, treści są często wstawiane automatycznie, jednak są wówczas czerpane bezpośrednio z tłumaczeń wykonanych ludzką ręką. Rolą tłumacza lub tłumaczki jest sprawdzenie, czy taka podpowiedź pamięci tłumaczeniowej pasuje do kontekstu w nowym tekście i jego dostosowanie, jeżeli zachodzi taka konieczność. Bywa, że narzędzia CAT oferują możliwość korzystania z tłumaczeń maszynowych (na przykład: jeśli nie uda się znaleźć podobnego segmentu w pamięci tłumaczeniowej, używane jest tłumaczenie maszynowe, które następnie jest sprawdzane przez osobę pracującą nad danym projektem), jednak zawsze na wyraźne życzenie użytkownika – nigdy nie jest to ustawieniem domyślnym.

Pamięci tłumaczeniowe służą nie tylko tłumaczom lub agencjom, ale głównie klientowi
Z racji mniejszego nakładu pracy dostawcy usług językowych nierzadko oferują zniżki za te fragmenty tłumaczenia, które są tzw. „dopasowaniem”. locatheart należy do takich właśnie agencji.
„Dopasowania” podpowiadają, jak duże jest podobieństwo między danym segmentem (zazwyczaj chodzi o zdanie) a tym, który znajduje się w pamięci tłumaczeniowej. Stopień dopasowania może wahać się między 0% a 100%. Podobieństwo wylicza Trados, zapewniając przy okazji analizę zawierającą odpowiednie statystyki, na podstawie których przygotowujemy wycenę. Do każdego przedziału procentowego przypisywany jest współczynnik, który podpowiada nam, jaki ułamek ceny standardowej powinien zostać zapłacony za wybrane segmenty. Dla przykładu:
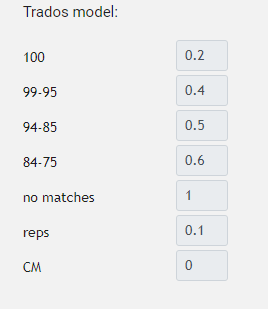
W przypadku tekstu, który składa się głównie ze stuprocentowych dopasowań (tj. identycznych fragmentów, które znajdują się w pamięci tłumaczeniowej) – i tylko niektóre z segmentów są nowe („no matches” – brak dopasowań) – należna stawka za słowo ulegnie znacznemu zmniejszeniu. Jeśli interesują Cię dokładne obliczenia lub chcesz wiedzieć, czym są „reps” i „CM”, polecamy nasz artykuł. Zapewne nie umknęło także Twojej uwadze, że dzięki pamięci tłumaczeniowej każdy kolejny projekt staje się coraz bardziej opłacalny ze względu na korzyści skali. Pisaliśmy również i o tym aspekcie.
Same superlatywy?
Po przeczytaniu tego artykułu, zachwalającego technologię pamięci tłumaczeniowych, pewnie zastanawiasz się, czy istnieją także jakieś wady. Jak w większości przypadków wartość narzędzia w dużej mierze zależy od jego użytkownika. Pamięci tłumaczeniowe są bardzo przydatnymi bazami danych, jednak do pewnego stopnia są tak wydajne jak tłumacz, który z nich korzysta.
Może się zdarzyć, że początkujący językowiec będzie zbytnio polegał na propozycjach programu i nie zauważy, że automatycznie wstawione zdanie różni się od oryginału. Początkujący tłumacz może też nie zauważyć, że podpowiedź z bazy o 100% podobieństwie może różnić się kontekstem i wymagać dostosowania. Dlatego ważne jest, aby pamięć tłumaczeniowa została wykorzystana w pełni przez doświadczonych tłumaczy, dobrze znających wszelkie zawiłości oprogramowania wspierającego tłumaczenia. Tacy właśnie językowcy pracują z locatheart.




Dodaj komentarz