

A translation to remember – what is translation memory and how it’s leveraged by linguists and agencies to provide excellent translations
In one of our previous texts we described tools that we employ to streamline locatheart’s localisation process. A large part of those is Trados, a CAT (computer-assisted-translation) tool that is the gold standard for translation industry. One of its most helpful features is the use of translation memories (TMs): “databases of all past projects, with original texts saved alongside their translations”.
Casual clients of translation agencies may not know much about TMs, as what they are interested in is the end product – an impeccable text in another language. Nevertheless, it is very useful to get a good understanding of translation memories, as in fact, a pricing system based on them is beneficial to the client.
What exactly is a translation memory
Such an ever-growing collection of head-to-head content in two given languages serves as reference for translators assigned with future tasks. They may, for example, look up specific phrases that they think are likely to have already appeared earlier.
But this isn’t yet the most essential attribute of TMs. What’s the most important is their automated feature of filling suggested translations in for the translator. Suppose that a company orders a translation of its sales contract. A translation agency performs the task and sends a target version back. Some time later, another translation of a similar contract is required. Now, it’s concluded with a different contractor, and some provisions differ, but mostly it’s very repetitive compared to the first one.
Translation memory tools in action
Such a situation is a classic example of how translation memories are used. The whole bilingual content of the first contract is stored in the TM. With the memory attached to a Trados project, the software sees where there are segments that are identical in both contracts and automatically fills the stored text in.
In our example, this will happen with the majority of sentences. Sometimes, such as when a different company name appears, the program will also fill the old content in but notify the user that the segments are not identical. Similar, yes, but not exactly verbatim.
Here, the translator’s job is to update what’s been changed and save a new version. If there are any new segments, where no text is reused, translation will be performed from scratch. But still, the lion’s share of the job has been automated and work time is significantly reduced.
Depending on internal rules, the translator may either accept the pre-filled content without checking it, or verify whether no errors were made in the first project. Be that as it may, the bottom line is that with more time at their disposal, the linguist may complete their tasks quicker and thus the client will receive a ready text sooner.

TM is not machine translation
What likely needs emphasising at this point is that translation memory software has nothing to do with automated translation. Both processes are digital but that’s the only similarity. In machine translation content is automatically rendered into the target language by a computer program, based on algorithms, databases and a set of rules.
On the other hand, translation memories are simply tools to be used by translators which make their job easier. Granted, content is often automatically inserted but it’s taken directly from a human-made translation done earlier. The translator’s role here is to check if the translation memory hint fits the context of the new text and to adjust it if it’s necessary. Sometimes, CAT tools offer the possibility of using machine translation (for instance: if no similar segment is found in the TM, machine translation is performed and then proofread by a human) but it’s always at a user’s request – it’s never the default option.

TMs benefit not only the translator or agency but mainly the client
With less work to do, language service providers often offer discounts for parts of translated content that are so-called “matches”. locatheart is among the agencies that do employ this solution.
“Matches” tell you how similar a given segment (usually a sentence) is to one that is already stored in the translation memory. It can be between 0% and 100%. The similarity is calculated by Trados and an analysis displaying relevant statistics is provided, based on which we prepare a quotation. Each percentage bracket is assigned a coefficient which tells us what fraction of the full price should be paid for given segments. An example:
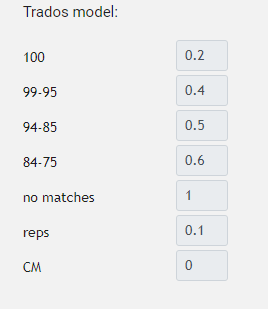
Should we have a text that is mostly 100% matches (that is, identical fragments are found in the translation memory), and only some of it is new (“no matches”), the payable base rate per word will be greatly reduced. If you’re interested in specific calculations, or would like to know what “reps” and “CM” are, you can refer to our article. You may also have noticed that with the use of translation memories, each subsequent project should be more profitable in terms of budget – due to the economies of scale. This is also true.
Always sunshine and rainbows?
Having read all the above praise of the TM technology, you might wonder if there’s any downside to using translation memories. As with most things, the value of a tool depends on its handler. Translation memories are exquisite databases but at least to some degree they’re as efficient as the translator who uses them.
It may happen that a rookie linguist will be too lenient with the software’s suggestions and won’t notice that a pre-filled sentence is different from the original. In some instances, a hint from the database with a 100% match will be different in context and require necessary adjustments. Therefore, it’s important that TMs are used to their full potential by experienced translators who are familiar with all caveats of computer-assisted translation. At locatheart, we work with such linguists.




Leave a Reply